About
Hello! I’m Arthur Conmy. I’m a Research Engineer at Google DeepMind, on the Language Model Interpretability team. I like to work on making interpretability useful, and am also thinking about thinking models and unfaithful Chain-of-Thought at the moment too.
I try and read things sometimes too (sadly not updated in some time).
Research
The below summary is highly outdated, and I have much more recent work from GDM and external in my Google Scholar.
-
Copy Suppression: Comprehensively Understanding an Attention Head
Callum McDougall,* Arthur Conmy,* Cody Rushing,* Thomas McGrath, Neel Nanda (* denotes equal contribution): arXiv preprint arXiv:2310.04625 (2023)
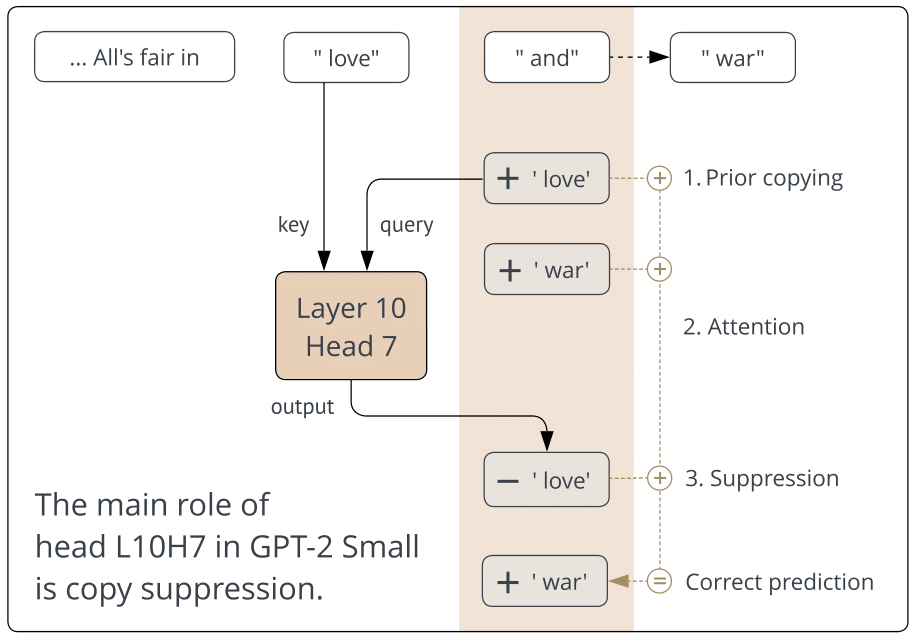
-
Towards Automated Circuit Discovery for Mechanistic Interpretability
Arthur Conmy, AN Mavor-Parker, A Lynch, S Heimersheim, A Garriga-Alonso: NeurIPS 2023 Spotlight arXiv:2304.14997 (2023)
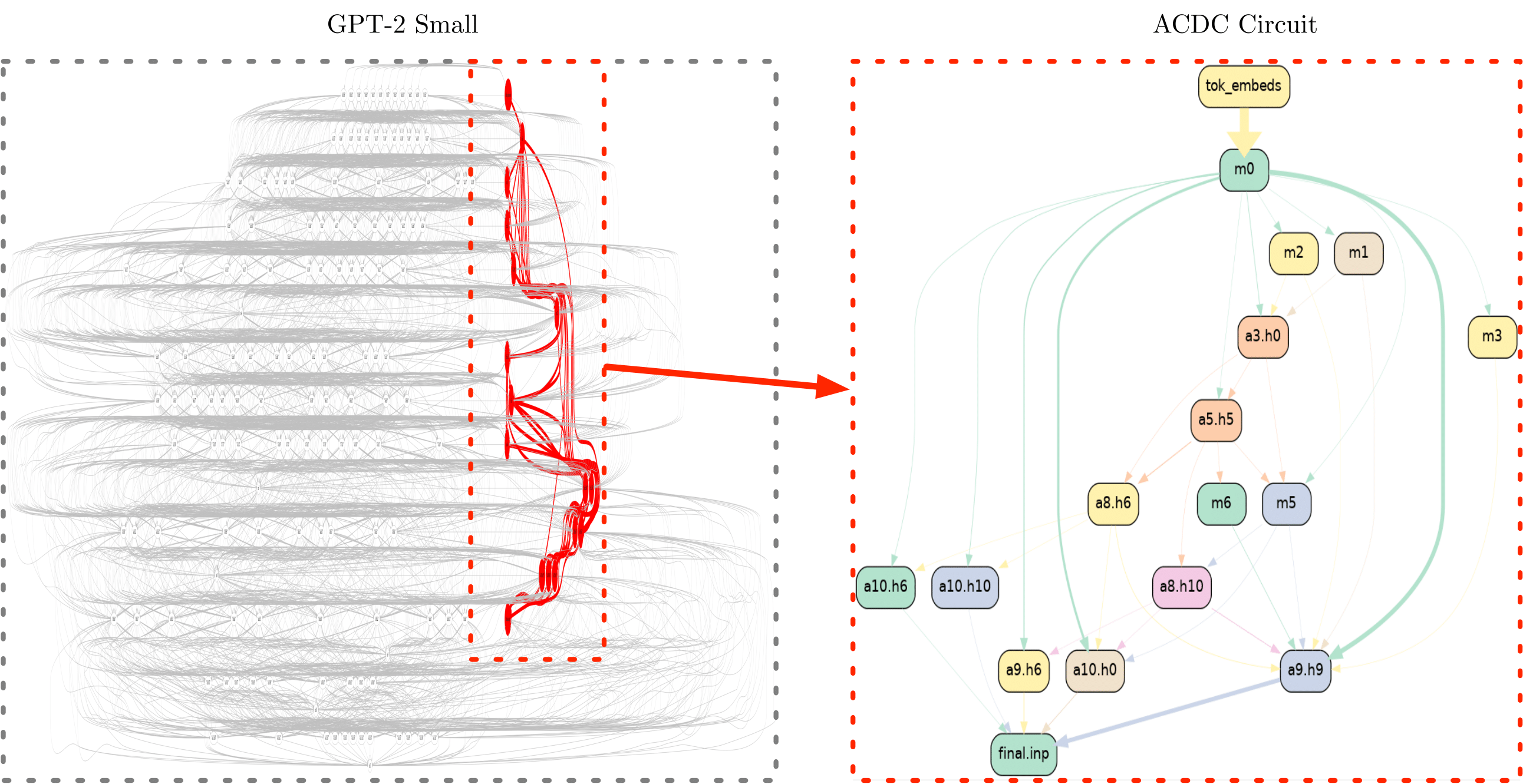
-
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
K Wang, A Variengien, Arthur Conmy, B Shlegeris, J Steinhardt
Proceedings of ICLR 2023 arXiv:2211.00593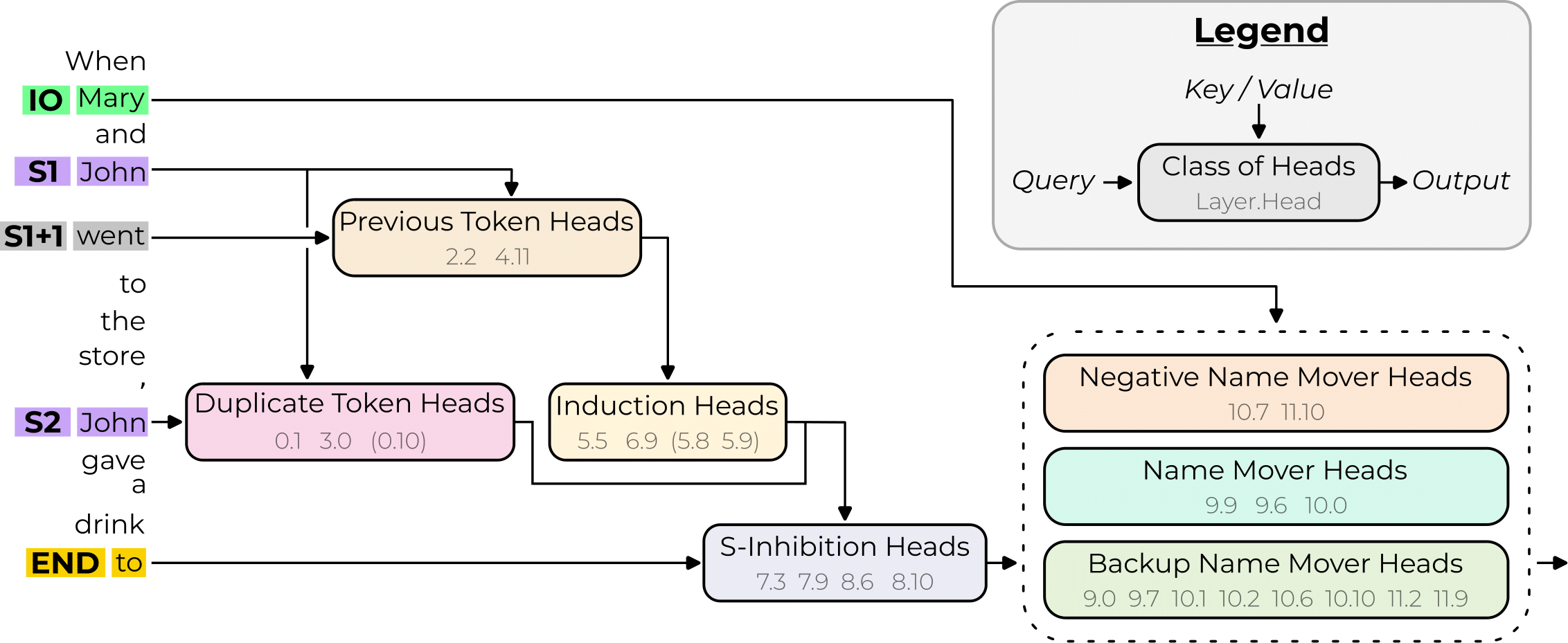
-
StyleGAN-induced data-driven regularization for inverse problems
Arthur Conmy, S Mukherjee, CB Schönlieb
Proceedings of ICASSP 2022 arXiv:2110.03814
Experience
2023 - 2025 (present) Research Engineer at Google DeepMind, on the Language Model Interpretability team.
2023 - 2023 SERI MATS and Independent Research.
2022 - 2023 Redwood Research.
2021 - 2021 Meta. Software Engineering Intern.
2019 - 2022 Trinity College Cambridge Undergraduate Mathematics. Upper first class honours.
 Outside the Tower of London, July 2021.
Outside the Tower of London, July 2021.
For the future: 0ee063d506d9319ca159f53a7dd3879e65465e28926a02a35f9c6348ec00f1bf